system-design
How to Choose a Database
A comprehensive guide to selecting the right database for your system design needs, covering SQL vs NoSQL, CAP theorem, and consistency models.
How to Choose a Database
Choosing the right database is one of the most critical decisions in system design. It dictates your data models, scalability, consistency guarantees, and mostly, the complexity of your application code.
The Core Decision Framework

When evaluating databases, start with these fundamental questions:
- Structure of Data: Is your data highly structured (relational) or flexible (documents, key-value)?
- Query Patterns: Do you need complex joins and transactions, or simple key-based lookups?
- Scale Needs: Do you expect to scale vertically (bigger machine) or horizontally (sharding)?
- Consistency: Do you need strict ACID compliance or is Eventual Consistency acceptable?
1. Relational Databases (SQL)
Examples: PostgreSQL, MySQL, SQLite, Oracle.
Choose SQL when:
- You need strict ACID guarantees (Atomicity, Consistency, Isolation, Durability).
- Your data structure is stable and predictable.
- You require complex queries involving
JOINs across multiple tables. - Transactional integrity is paramount (e.g., banking, payments).
Best Practices:
- Normalization: Reduce redundancy and improve data integrity.
- Indexing: Critical for read performance, but be mindful of write penalties.
- Connection Pooling: Managing database connections efficiently is key for throughput.
2. NoSQL Databases
NoSQL is a broad category encompassing several types of databases designed for specific access patterns and scaling needs.
A. Key-Value Stores
Examples: Redis, DynamoDB, Memcached.
Choose when:
- Speed is the primary concern (often in-memory).
- Data is accessed via a unique key.
- You are building caching layers or session management.
B. Document Stores
Examples: MongoDB, Couchbase.
Choose when:
- Schema is flexible or evolving.
- Developers prefer working with JSON-like objects.
- You want to store data together that is accessed together (better locality).
C. Wide-Column Stores
Examples: Cassandra, HBase.
Choose when:
- You need massive write scalability (write-heavy workloads).
- You have high volume time-series data or logs.
- Query patterns are known in advance (query-first design).
D. Graph Databases
Examples: Neo4j, Amazon Neptune.
Choose when:
- Relationships between data are as important as the data itself.
- You need to traverse deep hierarchies or networks (e.g., social networks, recommendation engines).
E. 2026 Emerging Categories
Vector Databases With the rise of AI and LLMs, vector databases are essential for storing embeddings (lists of numbers representing semantic meaning).
- Examples: Pinecone, Milvus, Weaviate, or
pgvectorfor PostgreSQL. - Use for: Semantic search, RAG (Retrieval-Augmented Generation) applications.
NewSQL / Distributed SQL These systems break the old “SQL doesn’t scale horizontally” rule. They offer the familiar SQL interface and ACID transactions but with the horizontal scaling capabilities of NoSQL.
- Examples: CockroachDB, YugabyteDB, Google Spanner.
- Use for: Systems needing both massive scale and strict consistency (e.g., global financial ledgers).
3. The CAP Theorem
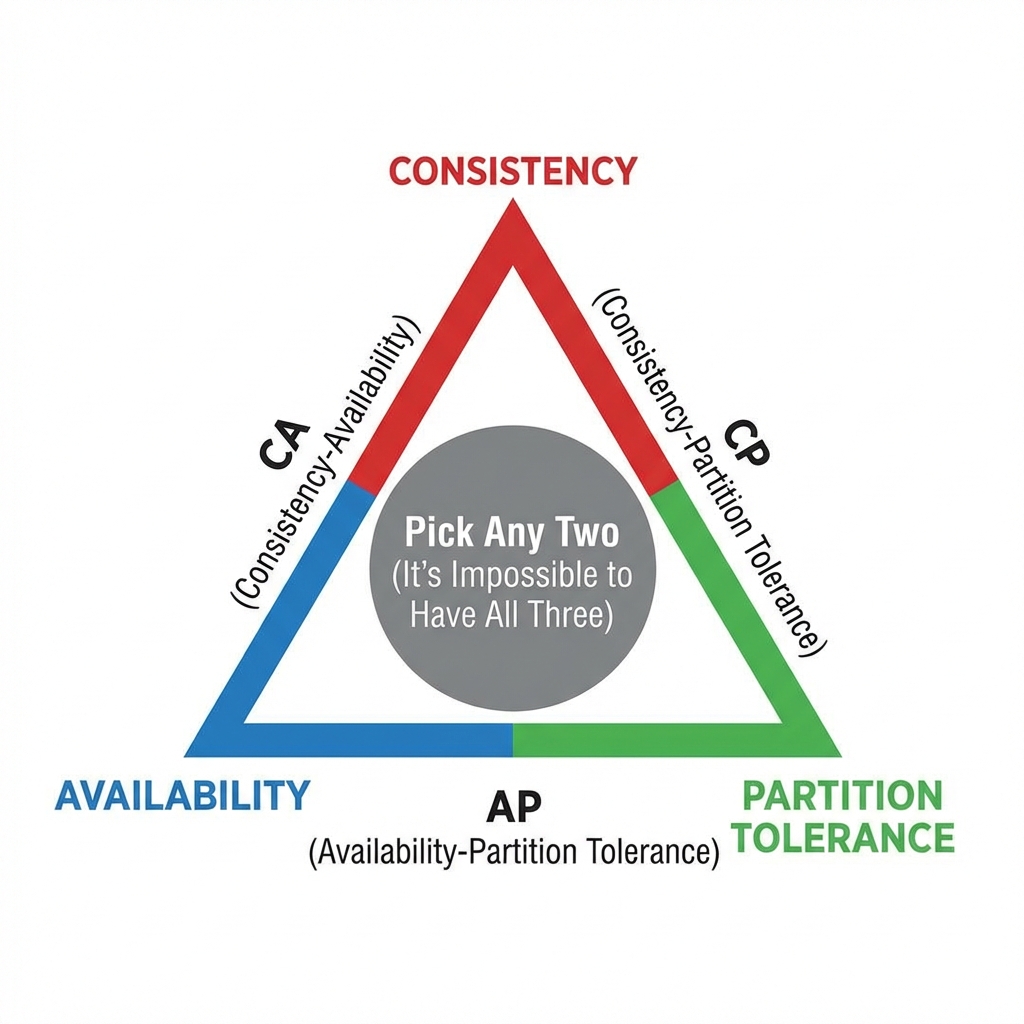
Understanding the CAP theorem is essential for distributed databases. It states that a distributed system can only provide two of the following three guarantees:
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
The “Pick 2” Myth: In a distributed system, network partitions (P) are inevitable. You cannot “choose” to avoid them. Therefore, the real choice is between Consistency (CP) and Availability (AP) when a partition occurs. “CA” systems are essentially non-distributed monoliths.
Beyond CAP: PACELC Theorem: Many modern engineers prefer the PACELC formulation. It states:
-
If there is a Partition (P), how does the system trade off Availability (A) and Consistency (C)?
-
Else (E), when the system is running normally (no partition), how does it trade off Latency (L) and Consistency (C)?
-
CP Systems: HBase, MongoDB (default). Prioritize consistency during partitions.
-
AP Systems: Cassandra, DynamoDB. Prioritize availability during partitions.
4. Quantitative Factors: Workload Types
Don’t just look at structure; look at how you use the data.
Read-Heavy vs. Write-Heavy
- Read-Heavy: standard B-Tree based databases (Postgres, MySQL) or caching layers (Redis) excel here.
- Write-Heavy: Log-Structured Merge-Tree (LSM-Tree) databases are optimized for massive ingestion.
- Recommendation: Cassandra, ScyllaDB, leveldb.
OLTP vs. OLAP
- OLTP (Online Transaction Processing): Fast, short transactions (e.g., “User bought item X”).
- Use: PostgreSQL, MySQL.
- OLAP (Online Analytical Processing): Complex aggregate queries on huge datasets (e.g., “Average revenue per user over the last 5 years”).
- Use: Snowflake, ClickHouse, BigQuery. Do not run these heavy reports on your production OLTP database.
5. Real World Case Studies
- Discord (Messages): Discord stores billions of messages. They migrated from MongoDB to Cassandra (and later ScyllaDB) because they needed massive write throughput and availability. A message ID is the key, and they don’t need complex JOINs on chat logs.
- Instagram (User Data): Despite having over a billion users, Instagram runs on PostgreSQL. They handle scale by “sharding” (splitting data across thousands of servers) based on User ID. It proves SQL can scale if engineered correctly.
- Facebook (Social Graph): To manage friends, likes, and connections, Facebook built TAO, a distributed graph data store. A relational DB would struggle with the query “Friends of my Friends who like X”.
Summary: A Quick Cheatsheet
| Need | Recommendation |
|---|---|
| Financial Transactions / ACID | PostgreSQL / MySQL |
| High Speed Caching | Redis |
| Flexible Schema / Rapid Prototyping | MongoDB |
| Massive Write Volume / IoT | Cassandra |
| Complex Relationships / Social Graph | Neo4j |
| Full Text Search | Elasticsearch |
Most modern systems use Polyglot Persistence, meaning they use multiple databases for different parts of the system (e.g., Postgres for main data, Redis for caching, Elasticsearch for search).
Comments