system-design
Latency Numbers Every Programmer Should Know (2026 Edition)
A first-principles look at how long things actually take. From L1 cache to cross-atlantic packets.
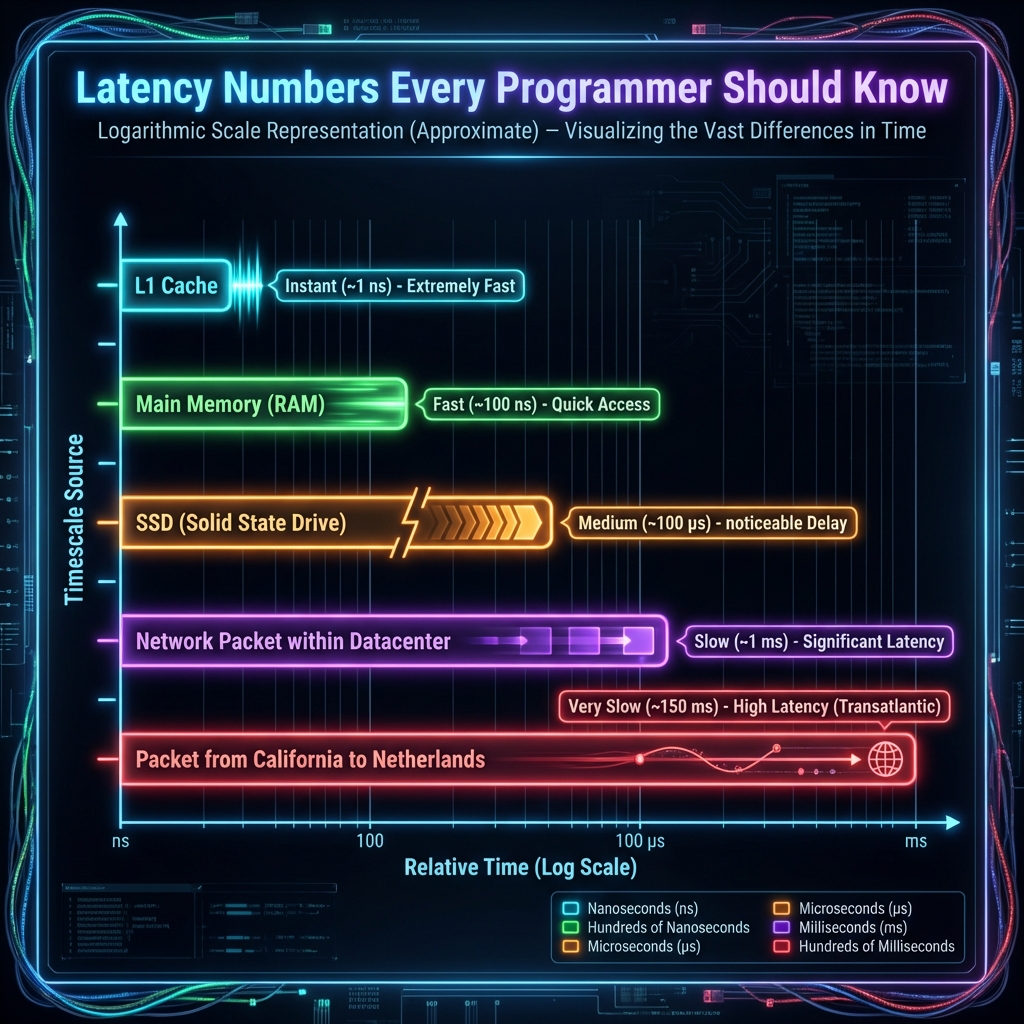
Latency Numbers Every Programmer Should Know
Dr. Jeff Dean originally popularized this list at Google. Knowing these orders of magnitude is the difference between designing a system that feels “instant” and one that feels “broken”.
The Human Scale Metaphor
If 1 CPU cycle (0.3ns) was 1 second, then:
- L1 Cache Access:
0.5 ns→ 1.5 seconds (Picking up a pen) - L2 Cache Access:
7 ns→ 23 seconds (Walking to the bookshelf) - Main Memory (RAM):
100 ns→ 5.5 minutes (Walking to the corner store) - NVMe SSD Read:
15 µs→ 14 hours (Driving to the next city) - Disk Seek (HDD):
10 ms→ 1 year (Sailing around the world) - Packet CA -> Netherlands:
150 ms→ 15 years (A significant portion of your life)
The Real Numbers (2026)
Hardware has gotten faster, but the ratios remain brutal.
| Operation | Time | Notes |
|---|---|---|
| L1 Cache Reference | 0.5 ns | Basically free. |
| Branch Misprediction | 2.5 ns | This is why if statements in tight loops matter. |
| L2 Cache Reference | 7 ns | 14x slower than L1. |
| Mutex Lock/Unlock | 25 ns | Concurrency is not free. |
| Main Memory Reference | 100 ns | The “Memory Wall”. |
| Compress 1KB w/ Zippy | 10 µs | CPU is fast at math. |
| Send 2KB over 1Gbps Network | 20 µs | Networking is surprisingly fast locally. |
| Read 1MB sequentially from RAM | 250 µs | Bandwidth is high. |
| Round trip within Datacenter | 500 µs | The “microservices tax”. |
| Read 1MB sequentially from SSD | 1 ms | Flash storage is a miracle. |
| Disk Seek (HDD) | 10 ms | Spinning rust is the bottleneck. Avoid it. |
| Packet CA -> Netherlands | 150 ms | The speed of light is a hard limit. |
Why This Matters for System Design
- Avoid Network Calls in Loops: A roundtrip to Redis (0.5ms) is 5,000x slower than reading from RAM. Get all your data in one batch.
- Locality is King: Sequential reads are orders of magnitude faster than random reads. This is why LSM Trees (Cassandra/Kafka) are faster for writes than B-Trees—they turn random writes into sequential writes.
- The “Microservices Tax”: Splitting a monolith into 10 services introduces 10x network hops. If your user request hits 50 services, that’s 50 * 0.5ms = 25ms of pure overhead, ignoring processing time.
First Principles Thinking
When designing a system, do “Back of the Envelope” math:
Goal: 100,000 requests per second. Constraint: Each request writes to DB. Math: Disk seek is 10ms (100 IOPS). Conclusion: You literally cannot do this with a single HDD. You need RAM buffering (Redis) or sequential appends (Kafka).
Don’t guess. Calculate.
Comments